I Tested 6 Local Coder LLMs on Real Apps. The Leaderboard Surprised Me.
I Tested 6 Local Coder LLMs on Real Apps
I got tired of guessing which local model to use for coding. Synthetic benchmarks tell you pass@1 scores. Cool. But will the model actually produce a working todo app? A playable Tetris? A calculator that respects operator precedence?
I tested six models on real tasks and scored them honestly. The results flipped my assumptions.
The Setup
Hardware: M3 Max MacBook Pro, 128GB RAM, all models via Ollama.
Models tested:
| Model | Size | Notes |
|---|---|---|
gemma4:26b-mlx-bf16 |
51 GB | Google, MLX quantization |
qwen3-coder-next |
51 GB | Alibaba, successor to qwen3-coder |
qwen3.5:35b-a3b-coding-nvfp4 |
21 GB | Alibaba, MoE |
laguna-xs.2 |
~14 GB | Poolside, brand new (released Apr 28) |
qwen3-coder:30b |
18 GB | Alibaba, the old king |
gpt-oss:20b |
13 GB | OpenAI open-weight |
Benchmarks — each model generates a complete app from a short prompt like “build me a modern todo app as a single HTML file. make it beautiful.”
| Benchmark | What it tests |
|---|---|
| Todo app | localStorage, filters, counters, delete, polish |
| Snake (HTML) | Canvas, game loop, movement, score tracking |
| Tetris | Piece rotation, collision, gravity, line clearing |
| Calculator | Precedence, parentheses, floats, clear |
| Markdown previewer | Live preview, headings, bold, italic, links, code blocks |
| Snake (pygame) | Python syntax, OOP, game architecture |
| Oi (greeting) | Portuguese detection, conciseness |
Validation: Every web app is driven by Playwright — real clicks, real keyboard input, real state assertions. No screenshots, no grep, no hoping it works.
Visual polish: Opus 4.7 pairwise comparisons across all model combinations. Not “rate this 1-5” (everything scores 3). Pairwise forces real decisions.
Code quality: Opus reviews the pygame code on a rubric (correctness, style, architecture, robustness, UX).
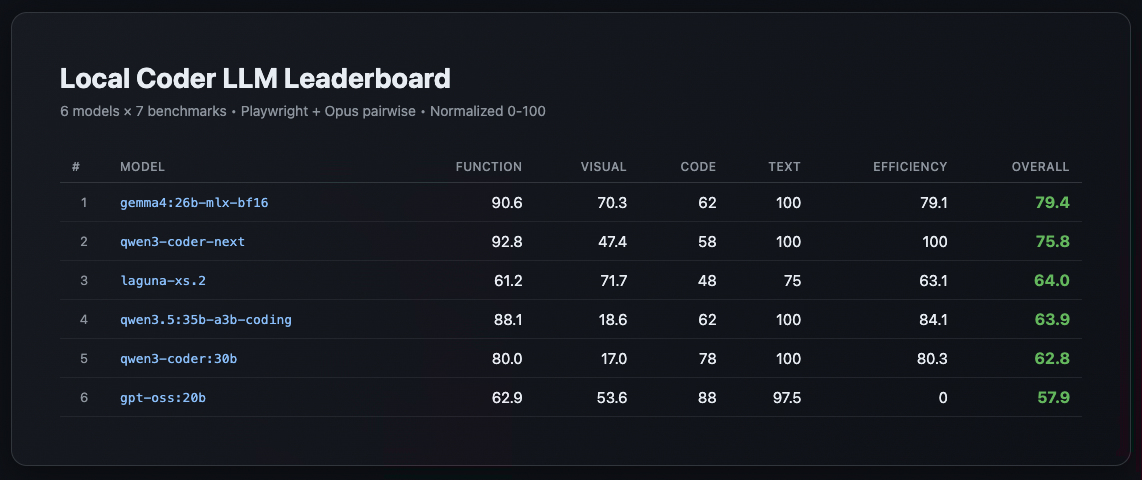
The Leaderboard
All columns normalized 0-100. Overall = weighted blend (Function 30%, Visual 30%, Code Review 15%, Text Quality 10%, Efficiency 15%).
| # | Model | Function | Visual | Code | Text | Efficiency | Overall |
|---|---|---|---|---|---|---|---|
| 1 | gemma4:26b-mlx-bf16 |
90.6 | 70.3 | 62 | 100 | 79.1 | 79.4 |
| 2 | qwen3-coder-next |
92.8 | 47.4 | 58 | 100 | 100 | 75.8 |
| 3 | laguna-xs.2 |
61.2 | 71.7 | 48 | 75 | 63.1 | 64 |
| 4 | qwen3.5:35b-a3b-coding-nvfp4 |
88.1 | 18.6 | 62 | 100 | 84.1 | 63.9 |
| 5 | qwen3-coder:30b |
80 | 17 | 78 | 100 | 80.3 | 62.8 |
| 6 | gpt-oss:20b |
62.9 | 53.6 | 88 | 97.5 | 0 | 57.9 |
Three Surprises
1. Gemma4 won. On visual polish.
I expected a Qwen coder sweep. Instead, gemma4:26b-mlx-bf16 produced the most visually polished apps across the board. Its todo app had glassmorphism, its snake had smooth animations, its Tetris had proper gradient backgrounds. Function score was near-tied with qwen3-coder-next, but visual put it over the top.
2. qwen3-coder:30b — the old king — fell to #5
The model I’d been using for months scored 100 on Snake HTML and Tetris (functionally perfect games) but produced ugly interfaces everywhere else. Markdown previewer barely worked (1/8 tier score). Visual polish: 17/100. Games: flawless. Everything else: plain.
3. gpt-oss:20b has the best code but the worst efficiency
Its pygame snake was the cleanest code I’ve seen from a local model — proper OOP, deque, direction-reversal prevention, docstrings. Opus gave it 88/100 on code review. But it burned 28K tokens across all benchmarks (most in the field), tanking its efficiency score to zero.
Per-Benchmark Breakdown
| Model | Todo | Snake | Tetris | Calc | Markdown | Pygame |
|---|---|---|---|---|---|---|
gemma4:26b-mlx-bf16 |
88 | 67 | 88 | 100 | 100 | ✅ |
qwen3-coder-next |
100 | 83 | 88 | 100 | 88 | ✅ |
laguna-xs.2 |
88 | 67 | 38 | 86 | 13 | ✅ |
qwen3.5:35b-a3b-coding-nvfp4 |
88 | 67 | 75 | 100 | 100 | ✅ |
qwen3-coder:30b |
88 | 100 | 100 | 100 | 13 | ✅ |
gpt-oss:20b |
63 | 67 | 88 | 43 | 25 | ✅ |
qwen3-coder:30b at 100/100 on Snake + Tetris but 13 on Markdown. The games king can’t build a text editor.
My recommendation
| Use case | Model |
|---|---|
| Daily coding assistant (all-rounder) | gemma4:26b-mlx-bf16 |
| Max functional correctness | qwen3-coder-next |
| Fast prototyping (smallest, quickest) | laguna-xs.2 |
| Games/interactive only | qwen3-coder:30b |
Try it yourself
The framework is open source: github.com/NightOwlCoder/local-llm-bench⇗
Add your models to bench.config.json, run ./bench.sh, and compare. Playwright validators included.
Part 1 of the Benchmarking Local LLMs series:
- I Tested 6 Local Coder LLMs on Real Apps (you are here)
- The Week My LLM Benchmark Was Lying to Me
- How to Benchmark Local LLMs Honestly
If you liked this post, you can share it with your followers⇗ and/or follow me on Twitter!