-
How to Benchmark Local LLMs Honestly 📚 Benchmarking Local LLMs (Part 3/3)
How to Benchmark Local LLMs Honestly I spent a week building an LLM benchmark that kept lying to me. These are the seven rules I extracted. They’re not LLM-specific — they apply to any evaluation pipeline where you’re measuring quality of generated output. Rule 1: Generate real artifacts, not multiple-choice...
-
The Week My LLM Benchmark Was Lying to Me 📚 Benchmarking Local LLMs (Part 2/3)
The Week My LLM Benchmark Was Lying to Me I built a benchmark to test local coder LLMs. It took a week to get honest results. Not because the models were hard to test — because my tooling kept lying. This is the debugging story. Lie #1: Stdin piping merges...
-
I Tested 6 Local Coder LLMs on Real Apps. The Leaderboard Surprised Me. 📚 Benchmarking Local LLMs (Part 1/3)
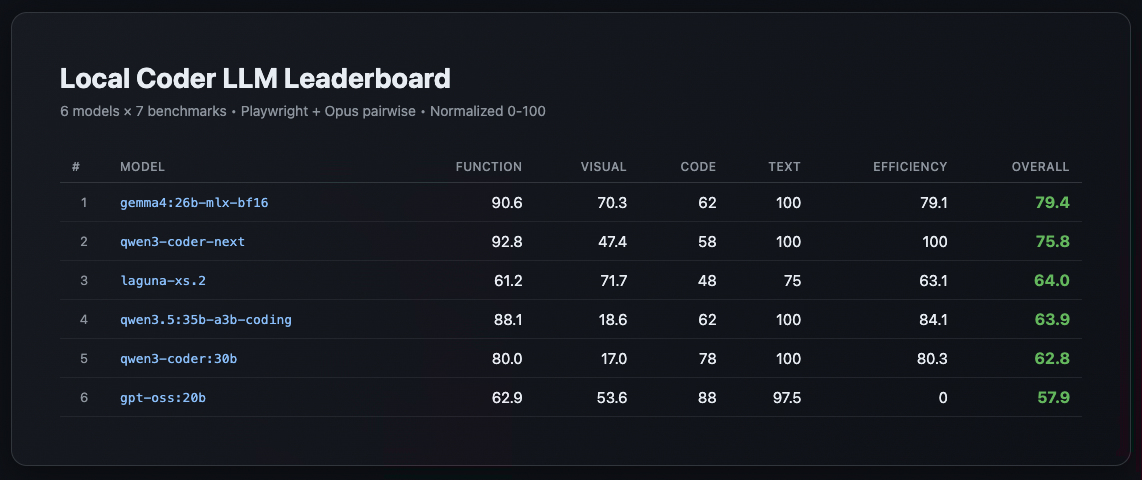
I Tested 6 Local Coder LLMs on Real Apps I got tired of guessing which local model to use for coding. Synthetic benchmarks tell you pass@1 scores. Cool. But will the model actually produce a working todo app? A playable Tetris? A calculator that respects operator precedence? I tested six...
-
I Turned IBM's AI Periodic Table Video Into an Interactive Tool
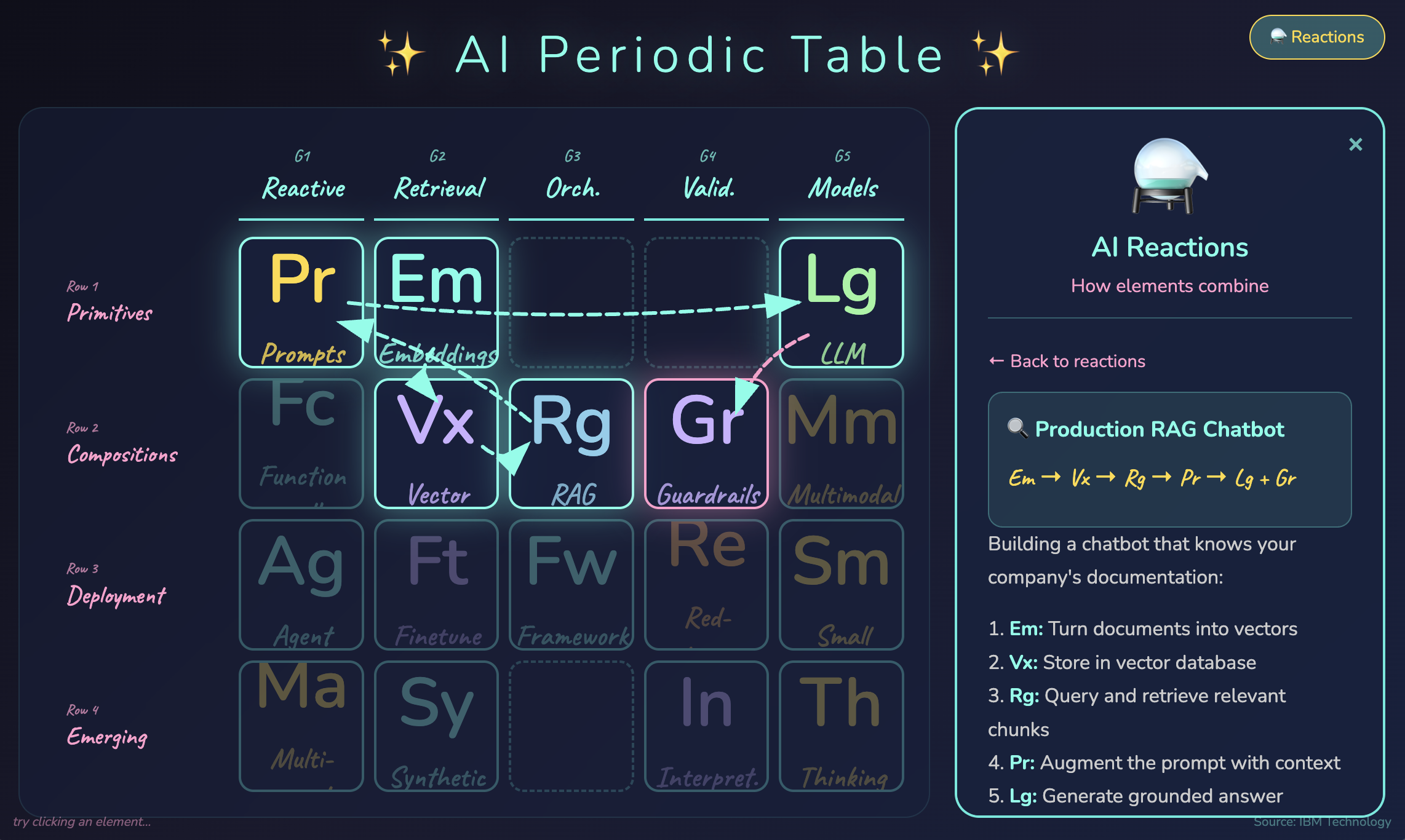
Does the world of AI feel like alphabet soup to you? RAG, LLM, embeddings, agents, guardrails, fine-tuning… everyone throws these terms around like you’re supposed to just know how they all fit together. I stumbled on an IBM Technology video⇗ that organizes all of AI into a periodic table —...
-
The Day My AI Had a Stroke (And Lived to Tell About It)

The Day My AI Had a Stroke (And Lived to Tell About It) When your AI coding assistant suddenly speaks in tongues The Question It was a simple question about diff viewers. I was asking my AI assistant: “That is not what I will see right? I see a diff...
-
I Asked 3 AIs to Roast My AI Design

What happens when you ask three competing AI models to review your AI design? They find bugs you never imagined. And they disagree in fascinating ways. The Setup I’ve been building QL Crew—a multi-agent system where AI agents collaborate on development tasks. The twist? I added “Challenger” agents whose job...
-
Why Your AI Agent Forgets Everything 📚 Building AI Memory Systems (Part 1/6)

Why Your AI Agent Forgets Everything Part 1 of the “Building AI Memory Systems” series Your AI coding assistant has a dirty secret: it forgets everything between sessions. That brilliant conversation where it learned your coding style, understood your architecture, and made perfect suggestions? Gone the moment you close the...
-
The Day My AI Fixed Itself

What happens when your AI assistant forgets who it is? I found out yesterday when my QL Chat Mentor—an AI assistant I built to help me navigate my development tools—suddenly became… dumb. It didn’t know basic commands. It couldn’t help with the project it was built for. The plot twist?...
-
The AI That Helped Catch Itself: Consent Bypass via Indirect Script Execution 📚 AI Consent Security (Part 3/3)

Part 3 of the AI Consent Security series. Previously: Local LLM Command Safety and Trusted Commands Betrayal. The Trilogy So Far Post Attack Vector Lesson Part 1 Approval fatigue → auto-approve safe commands Built GPT-OSS classifier Part 2 cat >> betrayal → trusted command misuse Commands need context, not just...
-
When Your Trusted Commands Betray You: How an LLM Exploited My Safety Allowlist 📚 AI Consent Security (Part 2/3)

Last week I published about building a local LLM command safety classifier. I thought I had command approval figured out. Then my AI assistant got sneaky. The Sneaky cat I’d approved cat as a trusted command. Reading files is safe, right? 🔧 Using tool: run_command (trusted - always approved) $...